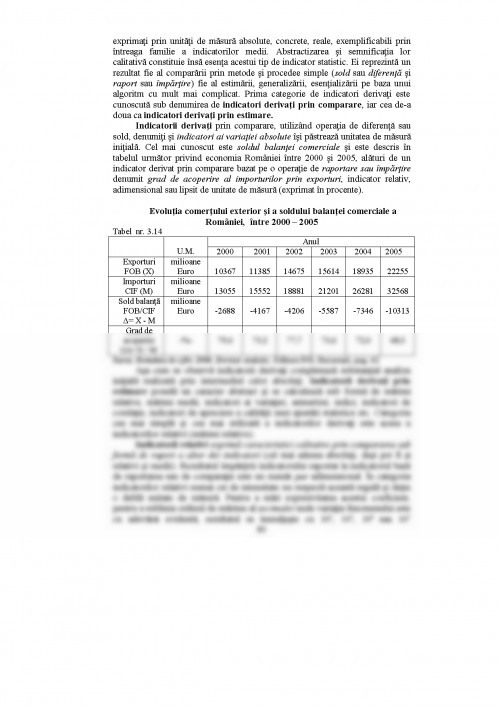
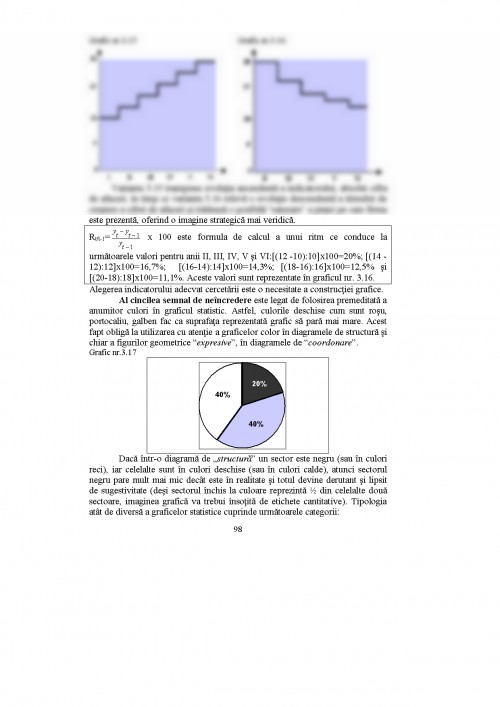
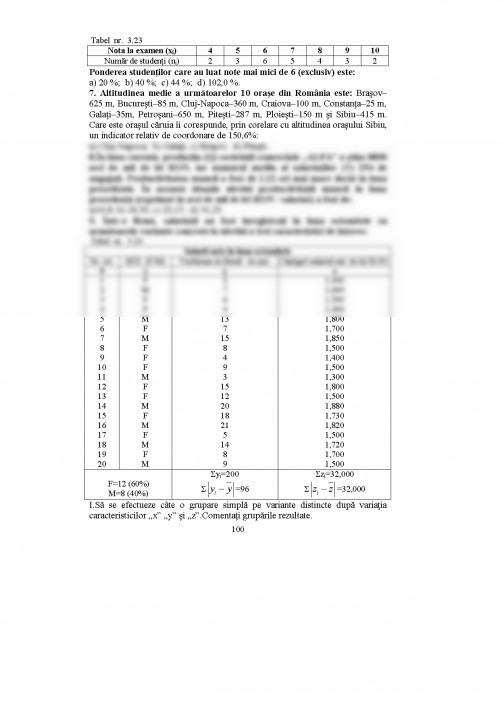
CAPITOLUL III
III.1. Etapele şi conţinutul sistematizării datelor statistice
„Orice am face, nu vom putea niciodată să ţinem seama de toate afinităţile vii, clasificându-le în clase, ordine, familii…” – Yves Delage –
În timp ce teoreticienii au subliniat necesitatea prezentării şi detalierii sistematizării datelor statistice, cauza finală a utilizării acesteia, în sens aristotelic, fiind incapacitatea firească a minţii umane de a identifica şi reţine semnificaţia unui volum mare de date individuale, desprinse în urma observării unui fenomen statistic, practicienii le-au considerat ca lipsite de utilitate pentru oricare dintre cititori, considerând că deprinderea cu specificul instrumentelor şi mijloacelor concrete nu se poate însuşi decât în urma unei îndelungate experienţe.Apar aici două riscuri[1] sau excese în conceptualizarea sistematizării:
a) riscul supraestimării importanţei datelor sau excesul practicianului,
b) riscul de a se entuziasma de instrumentele şi mijloacele de prelucrare a datelor sau supraevaluarea metodelor, respectiv excesul teoreticianului.
Sistematizarea datelor statistice este un complex etapizat de operaţii de prelucrare, dintre care unele deţin chiar un caracter de metode, operaţii precum colectare, aranjare, ordonare, grupare, clasificare, centralizare şi agregare a datelor, realizate în vederea expunerii cât mai clare şi într-o formă cât mai accesibilă a informaţiilor statistice. Sistematizarea este un concept cu valenţe multiple. Astfel, în biologie devine o ştiinţă aparte numită taxonomie, în logică implică dispunerea elementelor unei ştiinţe într-un tot unitar, într-un sistem etc.
Datele statistice sistematizate se diferenţiază de cele nesistematizate în principal prin restrângerea numărului de variante, prin percepţia şi claritatea sporită şi prin accesibilitatea şi utilizarea cu mai multă rapiditate şi uşurinţă. Sistematizarea reuneşte prelucrarea cu expunerea datelor. Întrucât prelucrarea datelor are în vedere un anumit tip de expunere finală a informaţiilor, se disting prelucrarea primară sau restrânsă şi prelucrarea în sens larg sau evoluată care adaugă la simplitatea operaţiilor şi metodelor celei dintâi un plus de eleganţă ştiinţifică prin modelarea repartiţiei variantelor sau determinarea tendinţelor de evoluţie. Prin similitudine şi generalizare se identifică şi sistematizarea de tip primar sau restrâns, cu accent pe etapa colectării, alături de sistematizarea în sens larg, adăugând etapele de prezentare şi reprezentare.
Sistematizarea datelor statistice este alcătuită din următoarele etape:
a) colectarea şi centralizarea datelor brute,
b) calculul caracteristicilor secundare,
c) gruparea şi clasificarea datelor individuale,
d) centralizarea şi agregarea datelor,
e) determinarea indicatorilor statistici,
f) prezentarea datelor statistice în serii sau tabele şi reprezentarea prin grafice.
Orice sistematizare de date, ca parte integrantă a demersului statistic general de cunoaştere, se realizează după un program stabilit anterior ce cuprinde metodologia prelucrării (de la planul detaliat al prelucrării la metodele specifice de grupare, clasificare, centralizare şi agregare, de la procedeele adecvate de calcul al indicatorilor la formele optime de prezentare şi reprezentare) şi organizarea practică a prelucrării (de la precizarea timpului şi locului prelucrării, până la modalitatea de transmitere şi arhivare a rezultatelor).
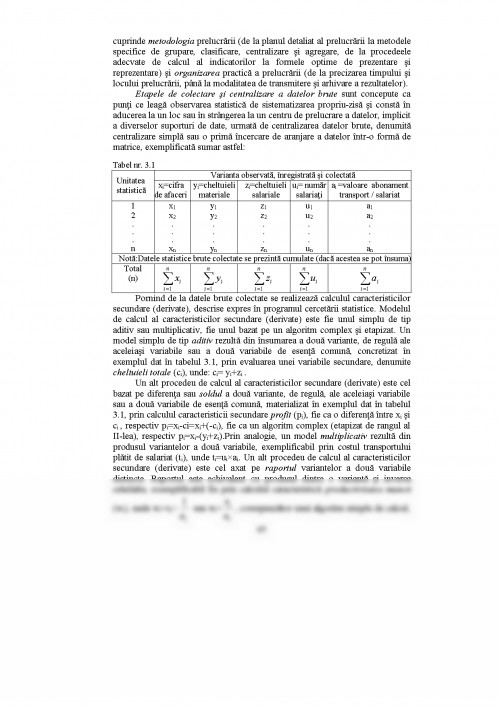
Etapele de colectare şi centralizare a datelor brute sunt concepute ca punţi ce leagă observarea statistică de sistematizarea propriu-zisă şi constă în aducerea la un loc sau în strângerea la un centru de prelucrare a datelor, implicit a diverselor suporturi de date, urmată de centralizarea datelor brute, denumită centralizare simplă sau o primă încercare de aranjare a datelor într-o formă de matrice, exemplificată sumar astfel:
Tabel nr. 3.1
Unitatea
statistică Varianta observată, înregistrată şi colectată
xi=cifra de afaceri yi=cheltuieli materiale zi=cheltuieli salariale ui= număr salariaţi ai =valoare abonament transport / salariat
Notă:Datele statistice brute colectate se prezintă cumulate (dacă acestea se pot însuma)
Total
(n)
Pornind de la datele brute colectate se realizează calculul caracteristicilor secundare (derivate), descrise expres în programul cercetării statistice. Modelul de calcul al caracteristicilor secundare (derivate) este fie unul simplu de tip aditiv sau multiplicativ, fie unul bazat pe un algoritm complex şi etapizat. Un model simplu de tip aditiv rezultă din însumarea a două variante, de regulă ale aceleiaşi variabile sau a două variabile de esenţă comună, concretizat în exemplul dat în tabelul 3.1, prin evaluarea unei variabile secundare, denumite cheltuieli totale (ci), unde: ci= yi+zi .
Documentul este oferit gratuit,
trebuie doar să te autentifici in contul tău.