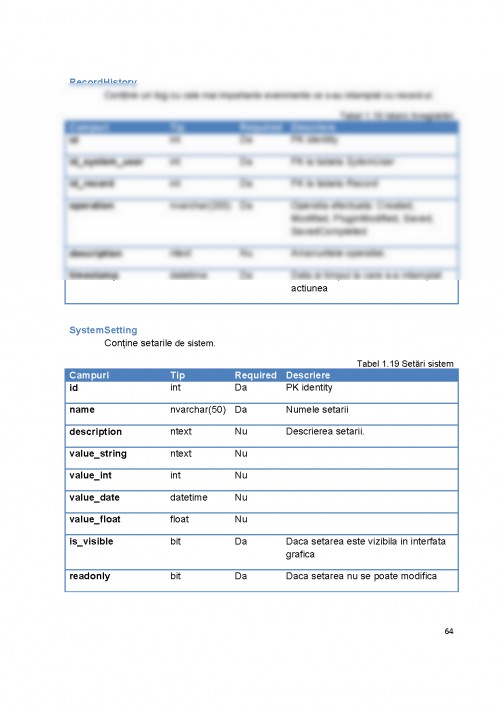
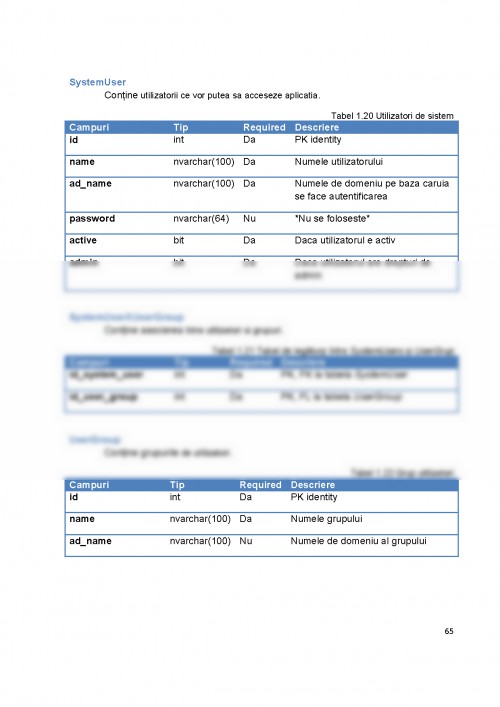
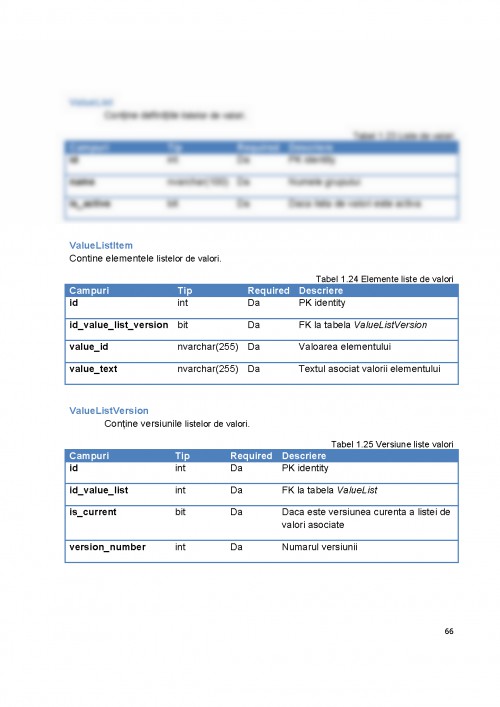
1. Introducere
Obiectivul acestei lucrari este de a face un studiu asupra actualelor tehnologii OCR i de a implementa o aplica.ie pentru firme mici si mijlocii care sa fie cat mai ieftina i care sa aduca o imbunata.ire considerabila a fluxului de lucru.
Optical Character Recognition (OCR) reprezinta conversia unei imagini in scris masina. Aceasta tehnologie a fost ini.ial dezvoltata in jurul anilor 1914 pentru telegraf si pentru a creea aparate de citire pentru nevazatori.
In timp aceasta tehnologie i-a gasit aplicabilitatea in cele mai variate domenii, de la armata pana la agentii de asigurari, pentru citirea unor simple coduri de bare pana la citirea unor texte scrise de mana.
Actuala tehnologie de OCR nu are o acurate.e de 100%. Pentru a avea o acurate.e cat mai mare pozele trebuie sa fie de calitate cat mai ridicata. O acurate.e buna este considerata intre 98% si 99%, una modesta intre 90%- 97%, iar sub 90% deja sunt mult prea multe gre.eli, caz in care programul produce mai multe probleme decat beneficii.
Programele bazate pe OCR au fost categorizate in 3 mari grupe : programe desktop si server, OCR online ( WebOCR sau OnlineOCR) i OCR orientat pe aplica.ie. Programele desktop si server sunt sisteme de inteligenta artificiala analitica care cauta grupuri de caractere in tabele dintr-o baza de date si pentru a asocial grupurile care formeaza cuvinte. Aplicatiile web de OCR sunt gratuite i disponibile publicului. Acestea au o acurate.e scazuta spre medie i consider ca nu au o aplicabilitate practica, cel pu.in pentru firme. Ultima categorie, OCR orientat pe aplicatie, a luat na.tere din nevoia de o recunoa.tere mai buna i mai sigura. Se mai nume.te i OCR customizat deoarece sunt create aplica.ii diferite pentru diverse tipuri de documente, cum ar fi carduri de identitate, carnete de ofer, car.i de vizita i multe altele.
Voi incerca sa dezvolt o aplica.ie care sa citeasca car.i de identitate i sa prelucreze informa.iile astfel ob.inute. Aplica.ia va putea fi configurabila usor pentru mai multe domenii fara nevoie de cod suplimentar, sau foarte pu.in. Pentru acest studiu am ales un cabinet notarial si unul de medicina, mai exact voi creea fluxuri pentru incheierea unui contract de vanzare-cumparare si unul pentru intocmirea unei adeverin.e medicale. Acestea vor fi generate in format PDF.
Dupa cum am spus costul aplica.iei trebuie sa fie cat mai mic, i de aceea am ales un motor de OCR gratuit, i anume Tesseract. Acesta este unul dintre pu.inele motoare gratuite i este cel mai bun dintre ele. Daca a. fi ales un motor performant, ar fi insemnat cre.terea pre.ului final al livrabilului considerabil deoarece pe langa licen.a de utilizare trebuie cumparata si licen.a de dezvoltare.
Livrabile deja existente si diverse proiecte bazate pe OCR vor fi prezentate in capitolul 2. De asemenea voi mentiona si ce SDK ( Software development kit) sunt disponibile si performan.a lor.
In capitolul ,,Dezvoltarea unei aplica.ii de recunoas.tere a documnetelor" voi exemplifica cateva scenarii care sper sa simuleze cat mai bine realitatea, i voi creea o lista de specificatii ale aplica.iei. Tot aici va fi prezentata arhitectura programului si a bazei de date, precum i considerente teoretice ale tehnologiilor folosite. In finalul capitolului va fi o analiza si o testare a func.ionalita.ii aplica.iei, i astfel voi determina ce imbunata.irii pot fi aduse.
Capitolul 4 reprezinta concluzia acestui studiu, daca acest OCR gratis este profitabil sau nu, i de asemenea voi men.iona si ce contribu.ii personale am adus.
2. Studiu asupra tehnologiilor actuale in domeniul OCR
In prezent OCR-ul este folosit cu succes in data-entry la scara mare. Voi prezenta cateva engine-uri de OCR, precum si cateva software-uri folosind aceasta tehnologie.
Engine-urile de OCR se impart in doua categorii, cele fara licenta, free, si cele cu licenta. Cele gratis sunt de cele mai multe ori si open-source. Ele au o acuratete scazuta si in mod evident nu beneficiaza de suport tehnic, sau exista o comunitate activa caz in care avem ansa sa ni se raspunda la unele intrebari. Un engine din aceasta categorie va fi folosit aici, i anume Tesseract, de la HP si Google. Alte engine-uri ar mai fi Puma.NET si Ocrad.
Marea majoritate din engine-uri sunt cele cu licenta, cum ar fi ABBYY FineReader, ExperVision TypeReader &RTK, OmniPage ( folosit de Microsoft Office Document Imaging). Dintre acestea se remarca OmniPage i ABBYY FineReader, care in fiecare an ca.tiga tot mai multe premii. Pot spune ca am avut ocazia sa lucrez cu sdk-ul de la ABBYY i pot spune exista o diferenta mare fata de engine-urile free.
In general software-urile care folosesc OCR nu se gasesc ca produs,
Pentru a descărca acest document,
trebuie să te autentifici in contul tău.